GPPM for disease progression modeling: basic use#
This tutorial introduces the use of the software GPMM available at https://gitlab.inria.fr/epione/GP_progression_model_V2.git.
Preparation#
We start by downloading and installing the package.
!pip install git+https://gitlab.inria.fr/epione/GP_progression_model_V2.git@fix_prediction
Collecting git+https://gitlab.inria.fr/epione/GP_progression_model_V2.git@fix_prediction
Cloning https://gitlab.inria.fr/epione/GP_progression_model_V2.git (to revision fix_prediction) to /tmp/pip-req-build-u4p6a4ky
Running command git clone -q https://gitlab.inria.fr/epione/GP_progression_model_V2.git /tmp/pip-req-build-u4p6a4ky
Running command git checkout -b fix_prediction --track origin/fix_prediction
Switched to a new branch 'fix_prediction'
Branch 'fix_prediction' set up to track remote branch 'fix_prediction' from 'origin'.
Building wheels for collected packages: gppm
Building wheel for gppm (setup.py) ... ?25l?25hdone
Created wheel for gppm: filename=gppm-2.0.0-cp37-none-any.whl size=15757 sha256=f272c7e528112ed3711a1cf8a8b977c983851f88fa957502769635b8e1013434
Stored in directory: /tmp/pip-ephem-wheel-cache-1_upv448/wheels/7b/4f/99/ae6da29607cff6cb811b4f4ca93aeabc1678a71e582534c93f
Successfully built gppm
Installing collected packages: gppm
Successfully installed gppm-2.0.0
Once GPPM is installed, we can import what is needed to run the tutorial
import GP_progression_model
# Setup
import matplotlib.pyplot as plt
import numpy as np
import os
#%matplotlib inline
## workaround for OS X
from sys import platform as sys_pf
if sys_pf == 'darwin':
matplotlib.use("TkAgg")
import GP_progression_model
from GP_progression_model import DataGenerator
import torch
import pandas as pd
import torch
Illustration on a synthetic case#
To understand the principle behind GPPM, let’s generate some data that will be later used to fit the model. The aim of GPPM is to reconstruct long-term temporal trajectories from the analysis of collections of short-terms observations. To get an idea of the principle, the following piece of code can be used to generate some synthetic trajectories for Nbiom biomarkers, and to sample idnvidual measurements from them.
os.mkdir('synth')
torch.backends.cudnn.benchmark = True
torch.backends.cudnn.fastest = True
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
## Parameters for progression curves and data generation
# Max value of the trajectories
# (we assume that they range from 0, healthy, to L, pathological)
L = 1
# time interval for the trajectories
interval = [-15,15]
# Number of biomarkers
Nbiom = 4
# Number of individuals
Nsubs = 30
# Gaussian observational noise
noise = 0.1
# We set the seed=111 as a reference for the further analysis
seed = 111
np.random.seed(seed)
# Creating random parameter sets for each biomarker's progression
flag = 0
while (flag!=1):
CurveParam = []
for i in range(Nbiom):
CurveParam.append([L,1*(0.5+np.random.rand()),noise])
if CurveParam[i][1] > 0.0:
flag = 1
# Calling the data generator
dg = DataGenerator.DataGenerator(Nbiom, interval, CurveParam, Nsubs, seed)
Here are the generated biomarkers trajectories (continuous lines) that we generated, along with observations from the different subjects (dashed segments). Each subject’s observation is assumed to be a noisy realisation from the original trajectory, evaluated over few samples. The number of time points available per subject is assigned randomly in the DataGenerator routine.
dg.plot('long')
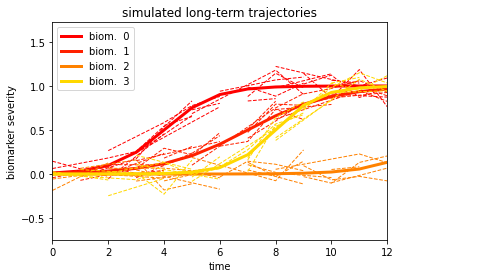
The difference in shape between biomarkers trajectories is due to the different in speed (the slope) and in the timing (the moment at which the trajectory starts increasing). Here is the timing associated with each biomarker:
# The time_shift indicates the moment at which each biomarker becomes abnormal
ground_truth_ts = dg.time_shift
dict_gt_ts = {}
for biom in range(Nbiom):
dict_gt_ts['biom_'+ str(biom)] = ground_truth_ts[biom]
pd.DataFrame(dict_gt_ts, index=['change time'])
| biom_0 | biom_1 | biom_2 | biom_3 | |
|---|---|---|---|---|
| change time | 4.0 | 7.0 | 14.0 | 8.0 |
We note that the change time associated to biomarker 2 is the furthest in time (at t=14), which means that the trajectory of this biomarker is constant along the entire observation interval.
We are ready not to generate our real observations, by resetting the individual observations above to the same origin. In this case, the time information is zero-centered for each subject:
dg.plot('short')
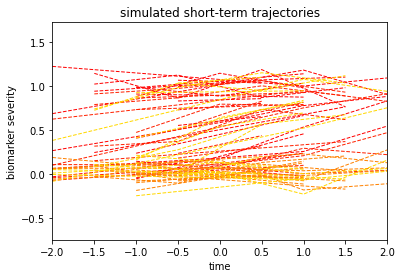
This kind of data is what is generally called spaghetti plot. The time axis is not related anymore directly to the original progression, but instead to an arbitrary unit (which may correspond for instance to a visit time). The goal of GPPM is to retrieve the long-term progressions from the spaghetti plot.
Let’s extract our synthetic data as a pandas DataFrame
df = dg.get_df()
The data frame has the following jey fields:
RID: the identifier for each individual,
time: the zero-centered time (e.g. visit time)
time_gt: the ground thruth time corresponding to position with respect to the long-term original synthetic trajectories
biom_*: the measurements for each biomarker and time point
We note that the structure of this data frame is very similar to the one of typical clinical and research datasets (e.g. ADNI).
df
| RID | time | biom_0 | biom_1 | biom_2 | biom_3 | time_gt | |
|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -1.0 | 0.979932 | 0.732228 | 0.011024 | 0.412049 | 8.0 |
| 1 | 0.0 | 1.0 | 1.138082 | 0.790095 | -0.039992 | 0.836982 | 10.0 |
| 2 | 1.0 | 0.0 | 0.991504 | 0.928058 | 0.122740 | 1.042216 | 11.0 |
| 3 | 2.0 | 0.0 | 0.292893 | 0.020794 | -0.023364 | 0.043239 | 3.0 |
| 4 | 3.0 | 0.0 | 1.012792 | 0.604817 | -0.092707 | 0.403241 | 8.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 61 | 28.0 | 0.0 | 0.371390 | 0.165749 | -0.118679 | -0.054633 | 4.0 |
| 62 | 29.0 | -2.0 | 0.062574 | -0.041898 | -0.056814 | -0.005067 | 0.0 |
| 63 | 29.0 | 0.0 | 0.182433 | 0.080903 | 0.027772 | -0.043215 | 2.0 |
| 64 | 29.0 | 1.0 | 0.256241 | 0.005242 | -0.016863 | -0.064809 | 3.0 |
| 65 | 29.0 | 2.0 | 0.544529 | 0.041862 | 0.040187 | 0.032076 | 4.0 |
66 rows × 7 columns
GPPM in action#
We are ready to apply GPPM to solve ou estimation problem:
# since the biomarkers are increasing from normal to abnormal states
# (resp. from 0 to L) we set the monotonicity constraint to 1 for each biomarker
monotonicity = np.repeat(1,Nbiom)
# the input is the generated synthetic data frame
input_data = df.drop(columns=['time_gt'])
# we convert the input data to the pieces that will be fed to GPPM
Xdata, Ydata, RID, list_biomarkers, group = GP_progression_model.convert_from_df(input_data,
['biom_' + str(i) for i in range(Nbiom)], time_var = 'time')
# here we call GPPM with the appropriate input
model = GP_progression_model.GP_Progression_Model(Xdata,Ydata, monotonicity = monotonicity, trade_off = 50,
names_biomarkers=['biom_' + str(i) for i in range(Nbiom)] )
Once created our GPPM object, we are ready to optimize. The optimization of GPPM iterates over two steps:
Estimation of the biomarkers trajectories. This is a regression problem, and is solved in GPPM by fitting a Gaussian Process (GP) mixed effect model to the observations. Gaussian processes are a fabulous family of non-parametric functions that can be used to solve a large variety of machine learning problems. In the case of GPPM, we impose that the trajectory must be monotonic over time, to describe steady evolutions from normal to pathological states.
Estimation of the subject-specific time reparameterization function. This step idetifies the most likely instant during the pathological evolution at which the individual has been observed, by optimizing the timing of the measurements with respect to the trajectories estimated above. The current version of the model support the estimation of both time-shift and scaling parameters.
Let’s run the optimization and observe how trajectories and individual parameters evolve over the iterations.
model.Optimize(plot = True, verbose = True, benchmark=True)
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Optimization step: 1 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 15.51 - Cost (fit): 355.66 - Cost (constr): 170.16|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Iteration 50 of 200 || Cost (DKL): 15.30 - Cost (fit): 238.45 - Cost (constr): 150.13|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 100 of 200 || Cost (DKL): 16.57 - Cost (fit): 205.81 - Cost (constr): 77.51|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 150 of 200 || Cost (DKL): 15.42 - Cost (fit): 226.96 - Cost (constr): 44.91|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 200 of 200 || Cost (DKL): 14.17 - Cost (fit): 184.17 - Cost (constr): 16.38|| Batch (each iter) of size 30 || Time (each iter): 0.03s
-- Time reparameterization --
Iteration 1 of 200 || Cost (DKL): 14.17 - Cost (fit): 240.22 - Cost (constr): 61.96|| Batch (each iter) of size 30 || Time (each iter): 0.04s
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Iteration 50 of 200 || Cost (DKL): 14.17 - Cost (fit): 163.64 - Cost (constr): 16.38|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 100 of 200 || Cost (DKL): 14.17 - Cost (fit): 176.37 - Cost (constr): 41.22|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 150 of 200 || Cost (DKL): 14.17 - Cost (fit): 164.56 - Cost (constr): 20.46|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 200 of 200 || Cost (DKL): 14.17 - Cost (fit): 155.17 - Cost (constr): 16.51|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Optimization step: 2 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 14.15 - Cost (fit): 204.55 - Cost (constr): 36.75|| Batch (each iter) of size 30 || Time (each iter): 0.04s
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Iteration 50 of 200 || Cost (DKL): 15.09 - Cost (fit): 154.31 - Cost (constr): 17.32|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 100 of 200 || Cost (DKL): 15.66 - Cost (fit): 103.17 - Cost (constr): 30.12|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 150 of 200 || Cost (DKL): 15.17 - Cost (fit): 112.74 - Cost (constr): 20.25|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Iteration 200 of 200 || Cost (DKL): 15.51 - Cost (fit): 110.74 - Cost (constr): 16.42|| Batch (each iter) of size 30 || Time (each iter): 0.03s
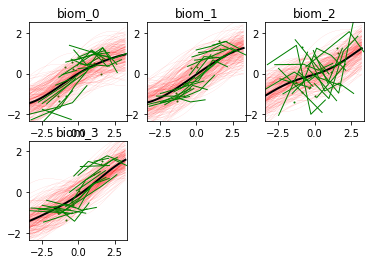
-- Time reparameterization --
Iteration 1 of 200 || Cost (DKL): 15.51 - Cost (fit): 66.27 - Cost (constr): 16.45|| Batch (each iter) of size 30 || Time (each iter): 0.05s
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Iteration 50 of 200 || Cost (DKL): 15.51 - Cost (fit): 87.60 - Cost (constr): 20.36|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Iteration 100 of 200 || Cost (DKL): 15.51 - Cost (fit): 58.95 - Cost (constr): 16.38|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Iteration 150 of 200 || Cost (DKL): 15.51 - Cost (fit): 54.43 - Cost (constr): 16.38|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Iteration 200 of 200 || Cost (DKL): 15.51 - Cost (fit): 62.00 - Cost (constr): 21.28|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Optimization step: 3 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 15.50 - Cost (fit): 47.49 - Cost (constr): 28.55|| Batch (each iter) of size 30 || Time (each iter): 0.04s
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Iteration 50 of 200 || Cost (DKL): 15.61 - Cost (fit): 21.12 - Cost (constr): 16.38|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 100 of 200 || Cost (DKL): 17.46 - Cost (fit): 0.83 - Cost (constr): 17.02|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Iteration 150 of 200 || Cost (DKL): 19.71 - Cost (fit): 8.68 - Cost (constr): 22.75|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 200 of 200 || Cost (DKL): 21.50 - Cost (fit): -26.30 - Cost (constr): 23.18|| Batch (each iter) of size 30 || Time (each iter): 0.03s
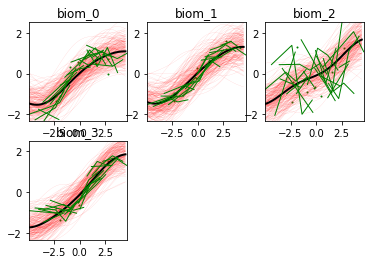
-- Time reparameterization --
Iteration 1 of 200 || Cost (DKL): 21.50 - Cost (fit): 13.32 - Cost (constr): 17.05|| Batch (each iter) of size 30 || Time (each iter): 0.06s
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Iteration 50 of 200 || Cost (DKL): 21.50 - Cost (fit): -10.16 - Cost (constr): 26.20|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 100 of 200 || Cost (DKL): 21.50 - Cost (fit): -39.39 - Cost (constr): 23.83|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 150 of 200 || Cost (DKL): 21.50 - Cost (fit): -14.59 - Cost (constr): 21.50|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 200 of 200 || Cost (DKL): 21.50 - Cost (fit): -48.67 - Cost (constr): 16.59|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Optimization step: 4 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 21.52 - Cost (fit): -17.67 - Cost (constr): 16.49|| Batch (each iter) of size 30 || Time (each iter): 0.05s
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Iteration 50 of 200 || Cost (DKL): 23.31 - Cost (fit): -38.82 - Cost (constr): 20.30|| Batch (each iter) of size 30 || Time (each iter): 0.05s
Iteration 100 of 200 || Cost (DKL): 26.56 - Cost (fit): -51.46 - Cost (constr): 16.40|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 150 of 200 || Cost (DKL): 26.74 - Cost (fit): -53.30 - Cost (constr): 23.91|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Iteration 200 of 200 || Cost (DKL): 30.27 - Cost (fit): -52.75 - Cost (constr): 17.37|| Batch (each iter) of size 30 || Time (each iter): 0.03s
-- Time reparameterization --
Iteration 1 of 200 || Cost (DKL): 30.27 - Cost (fit): -79.87 - Cost (constr): 22.59|| Batch (each iter) of size 30 || Time (each iter): 0.04s
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Iteration 50 of 200 || Cost (DKL): 30.27 - Cost (fit): -85.82 - Cost (constr): 23.56|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 100 of 200 || Cost (DKL): 30.27 - Cost (fit): -88.86 - Cost (constr): 16.39|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 150 of 200 || Cost (DKL): 30.27 - Cost (fit): -84.62 - Cost (constr): 18.26|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 200 of 200 || Cost (DKL): 30.27 - Cost (fit): -70.81 - Cost (constr): 18.83|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Optimization step: 5 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 30.23 - Cost (fit): -51.87 - Cost (constr): 18.02|| Batch (each iter) of size 30 || Time (each iter): 0.05s
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Iteration 50 of 200 || Cost (DKL): 32.13 - Cost (fit): -63.44 - Cost (constr): 18.78|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 100 of 200 || Cost (DKL): 33.72 - Cost (fit): -65.22 - Cost (constr): 17.61|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Iteration 150 of 200 || Cost (DKL): 34.77 - Cost (fit): -41.57 - Cost (constr): 20.51|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 200 of 200 || Cost (DKL): 36.42 - Cost (fit): -110.31 - Cost (constr): 21.96|| Batch (each iter) of size 30 || Time (each iter): 0.03s
-- Time reparameterization --
Iteration 1 of 200 || Cost (DKL): 36.42 - Cost (fit): -112.59 - Cost (constr): 17.11|| Batch (each iter) of size 30 || Time (each iter): 0.03s
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Iteration 50 of 200 || Cost (DKL): 36.42 - Cost (fit): -98.19 - Cost (constr): 26.84|| Batch (each iter) of size 30 || Time (each iter): 0.04s
Iteration 100 of 200 || Cost (DKL): 36.42 - Cost (fit): -125.11 - Cost (constr): 28.69|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 150 of 200 || Cost (DKL): 36.42 - Cost (fit): -111.69 - Cost (constr): 16.38|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 200 of 200 || Cost (DKL): 36.42 - Cost (fit): -78.53 - Cost (constr): 17.14|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Optimization step: 6 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 36.50 - Cost (fit): -110.81 - Cost (constr): 16.67|| Batch (each iter) of size 30 || Time (each iter): 0.04s
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Iteration 50 of 200 || Cost (DKL): 38.18 - Cost (fit): -105.39 - Cost (constr): 23.05|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 100 of 200 || Cost (DKL): 39.09 - Cost (fit): -115.45 - Cost (constr): 23.37|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 150 of 200 || Cost (DKL): 40.47 - Cost (fit): -128.37 - Cost (constr): 22.59|| Batch (each iter) of size 30 || Time (each iter): 0.03s
Iteration 200 of 200 || Cost (DKL): 41.02 - Cost (fit): -137.26 - Cost (constr): 33.65|| Batch (each iter) of size 30 || Time (each iter): 0.03s
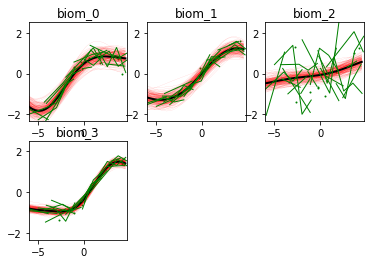
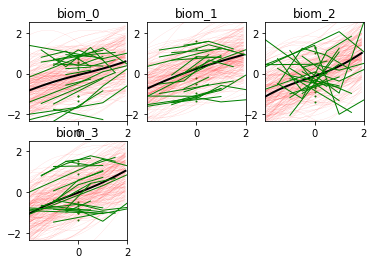
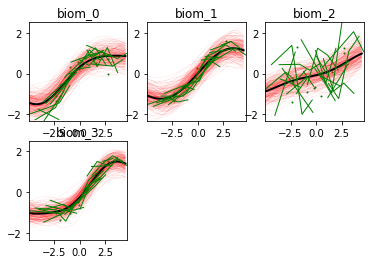
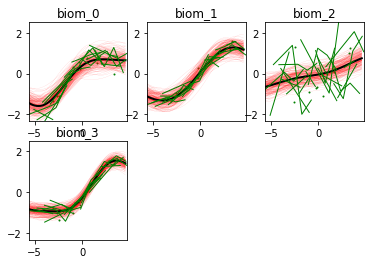
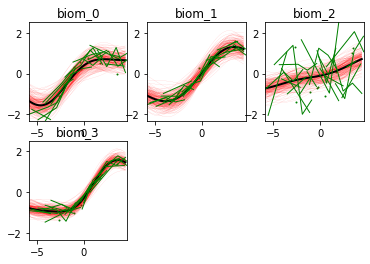
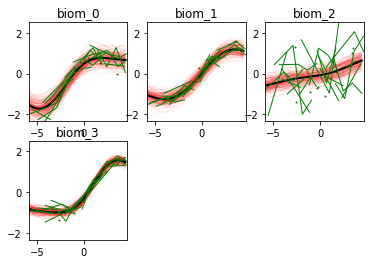
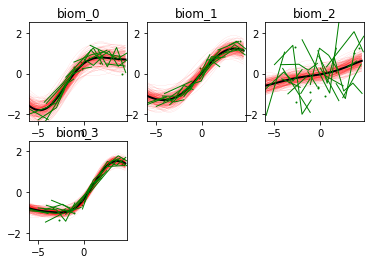
Here we go! The estimated trajectories can be observed with the command model.Plot()
model.Plot()
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
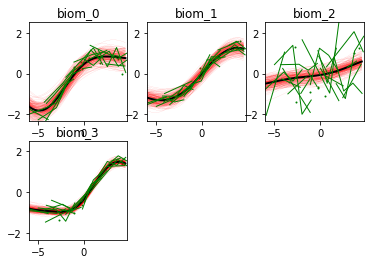
GPPM an produce a variety of figures that can be used to interpret the results and extract a lot of useful information about data and trajectories
#This command saves the fitted biomarkers trajectories in separate files
model.Plot(save_fig = './synth/')
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Let’s read the images one by one
plt.figure(figsize=(10,10))
for i in range(Nbiom):
plt.subplot(2,2,i+1)
fig_biom = plt.imread('./synth/biom_'+str(i)+'.png')
plt.imshow(fig_biom)
We note that the estimated uncertainty for biomarker 2 is large, and that the trajectory is mostly flat.
By plotting with the option join=True we can extract more information on the fitted trajectories:
# with the option
model.Plot(save_fig = './synth/', joint = True)
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
A key information for understanding the relationship between biomarkers is the estimated time of maximum change. This is the moment at which the speed of the estimated trajectory is maximum, and indicates the relative positioning (ranking) of the biomarkers when varying from normal to pathological stages.
plt.figure(figsize=(10,6))
plt.subplot(1,2,1)
timing = plt.imread('./synth/change_timing.png')
plt.imshow(timing, aspect='auto')
plt.title('Estimated trajectories timing')
plt.subplot(1,2,2)
dg.plot('long')
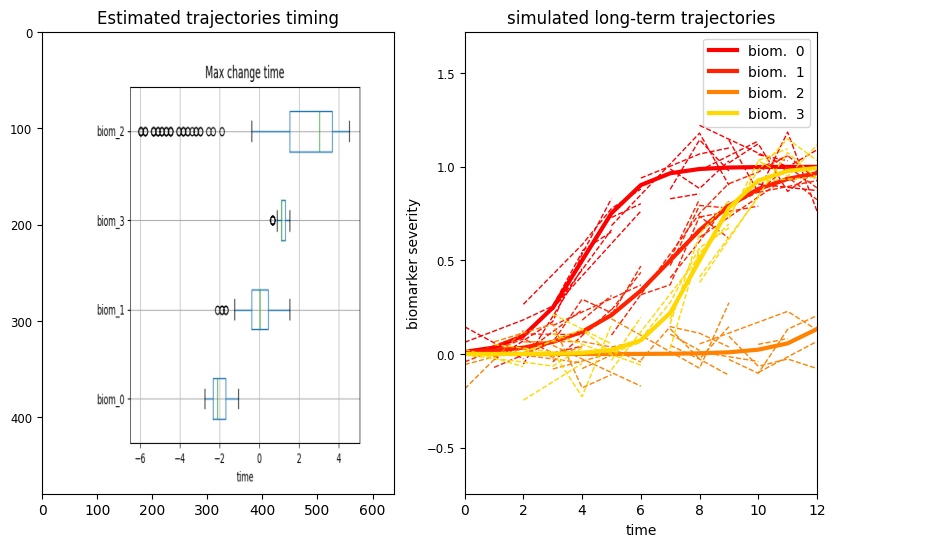
We observe that the order of the four biomarkers across the estimated time-axis correponds to the ground thruth change time generated for the synthetic data. The most interesting observation is that biomarker 2 is associated with very large uncertainty, since it is flat. In this case there is not a well defined transition time, and this leads to high uncertainty of the model: based on the data, it is not possible to establish when this biomarker is going to transition from normal to pathological values.
We can also quantify the magnitude of the trajectories of changes of each biomarker:
plt.figure(figsize=(10,6))
plt.subplot(1,2,1)
magnitude = plt.imread('./synth/change_magnitude.png')
plt.imshow(magnitude, aspect = 'auto')
plt.title('Estimated trajectories magnitude')
plt.subplot(1,2,2)
dg.plot('long')
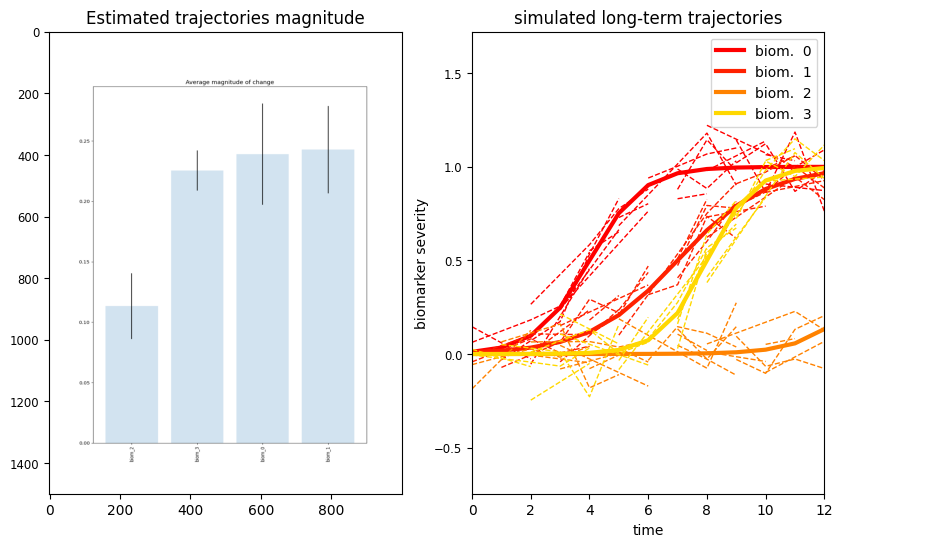
We can see that biomarker 2 is associated with the lowest amount of change across the estimated long-term progression. Biomarker 0 and 3 are the one changing the most, and this is in agreement with the synthetic trajectories originally generated.
Given the model, it is possible to estimate the time-shift (or disease severity) associated with each individual, based on the available set of biomarkers. This can be simply done with the following command:
pred_time_shift = model.PredictOptimumTime(input_data, id_var='RID', time_var='time')
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
pred_time_shift
| time | Time Shift | |
|---|---|---|
| RID | ||
| 0.0 | -1.0 | 1.530266 |
| 1.0 | 0.0 | 4.387256 |
| 2.0 | 0.0 | -3.112342 |
| 3.0 | 0.0 | 0.816019 |
| 4.0 | -1.0 | -2.755218 |
| 5.0 | 0.0 | -0.969600 |
| 6.0 | 0.0 | -0.255352 |
| 7.0 | -1.0 | 0.816019 |
| 8.0 | -2.0 | 0.101771 |
| 9.0 | -2.0 | 2.958761 |
| 10.0 | -2.0 | -2.398095 |
| 11.0 | 0.0 | 1.887390 |
| 12.0 | -1.5 | -2.398095 |
| 13.0 | -0.5 | 0.458895 |
| 14.0 | -1.0 | -2.398095 |
| 15.0 | -1.5 | 0.458895 |
| 16.0 | -1.0 | 3.673009 |
| 17.0 | -0.5 | -1.683847 |
| 18.0 | -2.0 | -2.755218 |
| 19.0 | -1.5 | 3.315885 |
| 20.0 | -0.5 | 3.673009 |
| 21.0 | -1.0 | 1.173143 |
| 22.0 | -1.5 | 3.315885 |
| 23.0 | -1.0 | -4.897961 |
| 24.0 | 0.0 | 4.387256 |
| 25.0 | 0.0 | -2.755218 |
| 26.0 | -0.5 | -0.969600 |
| 27.0 | 0.0 | -0.255352 |
| 28.0 | 0.0 | -2.398095 |
| 29.0 | -2.0 | -3.826590 |
We can plot the predicted individual time-shift against the ground truth time-shift generated for each individual.
ground_truth = dg.OutputTimeShift()
plt.scatter(pred_time_shift['Time Shift'],ground_truth)
plt.xlabel('estimated time-shift')
plt.ylabel('ground truth disease stage')
Text(0, 0.5, 'ground truth disease stage')
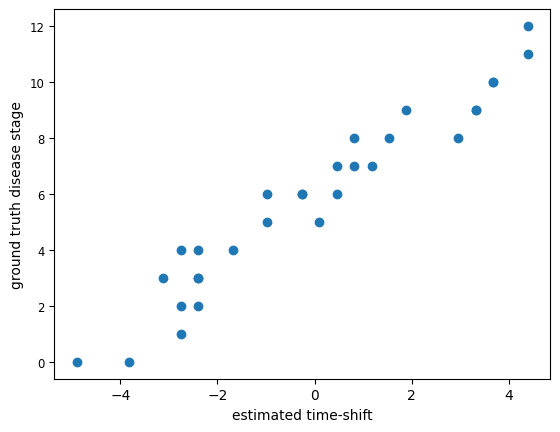
The estimated time-shift is in lage agreement with the original positioning of each individual in the time-axis of the long-term trajectories.
Modeling of longitudinal biomarkers form the (pseudo-)ADNI dataset#
This last section illustrates the use of GPPM on real data. We are going to work with a pseudo-version of ADNI. The dataset consists of biomarkers collected over time for 171 subjects. 82 individuals are healhty (NL), 752 are affected by mild cognitive impairment (MCI), and 82 are patients with Alzheimer’s disease (AD). The measurements were created based on the biomarker’s measures observed in the original ADNI dataset.
os.mkdir('real')
pseudo_adni = pd.read_csv('http://marcolorenzi.github.io/material/pseudo_adni.csv')
print(pseudo_adni.columns)
diags = { 'NL' : np.sum(pseudo_adni['group']==1),
'MCI' : np.sum(pseudo_adni['group']==2),
'AD' : np.sum(pseudo_adni['group']==3), }
diags
Index(['RID', 'Time', 'Hippocampus', 'Ventricles', 'Entorhinal', 'WholeBrain',
'ADAS11', 'FAQ', 'AV45', 'FDG', 'group'],
dtype='object')
{'AD': 320, 'MCI': 752, 'NL': 82}
GPPM in action#
As for the synthetic example, we first convert the original data frame into a GPPM input
biomarkers = ['Hippocampus', 'Ventricles', 'Entorhinal', 'WholeBrain',
'ADAS11', 'FAQ', 'AV45', 'FDG']
Xdata, Ydata, RID, list_biomarkers, group = GP_progression_model.convert_from_df(pseudo_adni,
biomarkers, time_var = 'Time')
In this case we need to specify a meaningful monotonicity constraint for each biomarkers. The monotonicity will reflect our knowledge on how each biomarker varies from normal to pathological values. For example, the brain volume decreases over time, and therefore the monotonicity constraint will be negative. On the contrary, the clinical score ADAS11 increases with more advanced pathological states, and therefore the monotonicity constraint will be positive.
We obtain:
dict_monotonicity = { 'Hippocampus' : -1, #decreasing
'Ventricles': 1, #increasing
'Entorhinal': -1, #decreasing
'WholeBrain': -1, #decreasing
'ADAS11': 1, #increasing
'FAQ': 1, #increasing
'AV45': 1, #increasing
'FDG': -1, #decreasing
}
We are ready to run and optimize GPPM on this dataset:
# trade off between data-fit and monotonicity
trade_off = 100
# create a GPPM object
model = GP_progression_model.GP_Progression_Model(Xdata,Ydata, names_biomarkers = biomarkers, monotonicity = [dict_monotonicity[k] for k in dict_monotonicity.keys()], trade_off = trade_off,
groups = group, group_names = ['NL','MCI','AD'], device = device)
model.model = model.model.to(device)
# Optimise the model
N_outer_iterations = 6
N_iterations = 200
model.Optimize(N_outer_iterations = N_outer_iterations, N_iterations = N_iterations, n_minibatch = 10, verbose = True, plot = False, benchmark = True)
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
Optimization step: 1 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 15.25 - Cost (fit): 319.07 - Cost (constr): 2140.06|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 50 of 200 || Cost (DKL): 15.11 - Cost (fit): 375.92 - Cost (constr): 875.30|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 100 of 200 || Cost (DKL): 17.36 - Cost (fit): 257.78 - Cost (constr): 466.63|| Batch (each iter) of size 9 || Time (each iter): 0.07s
Iteration 150 of 200 || Cost (DKL): 20.35 - Cost (fit): 226.63 - Cost (constr): 147.82|| Batch (each iter) of size 9 || Time (each iter): 0.07s
Iteration 200 of 200 || Cost (DKL): 22.76 - Cost (fit): 210.95 - Cost (constr): 116.81|| Batch (each iter) of size 9 || Time (each iter): 0.09s
-- Time reparameterization --
Iteration 1 of 200 || Cost (DKL): 22.76 - Cost (fit): 164.13 - Cost (constr): 134.60|| Batch (each iter) of size 9 || Time (each iter): 0.08s
Iteration 50 of 200 || Cost (DKL): 22.76 - Cost (fit): 213.85 - Cost (constr): 164.01|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 100 of 200 || Cost (DKL): 22.76 - Cost (fit): 229.10 - Cost (constr): 103.49|| Batch (each iter) of size 9 || Time (each iter): 0.10s
Iteration 150 of 200 || Cost (DKL): 22.76 - Cost (fit): 182.90 - Cost (constr): 188.14|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 200 of 200 || Cost (DKL): 22.76 - Cost (fit): 212.29 - Cost (constr): 107.95|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Optimization step: 2 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 22.79 - Cost (fit): 209.65 - Cost (constr): 200.35|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 50 of 200 || Cost (DKL): 23.85 - Cost (fit): 155.76 - Cost (constr): 136.65|| Batch (each iter) of size 9 || Time (each iter): 0.07s
Iteration 100 of 200 || Cost (DKL): 23.64 - Cost (fit): 136.93 - Cost (constr): 88.38|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 150 of 200 || Cost (DKL): 23.37 - Cost (fit): 130.74 - Cost (constr): 99.00|| Batch (each iter) of size 9 || Time (each iter): 0.07s
Iteration 200 of 200 || Cost (DKL): 23.29 - Cost (fit): 113.99 - Cost (constr): 93.18|| Batch (each iter) of size 9 || Time (each iter): 0.06s
-- Time reparameterization --
Iteration 1 of 200 || Cost (DKL): 23.29 - Cost (fit): 146.91 - Cost (constr): 67.48|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 50 of 200 || Cost (DKL): 23.29 - Cost (fit): 105.83 - Cost (constr): 58.19|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 100 of 200 || Cost (DKL): 23.29 - Cost (fit): 129.35 - Cost (constr): 44.85|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 150 of 200 || Cost (DKL): 23.29 - Cost (fit): 140.34 - Cost (constr): 67.39|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 200 of 200 || Cost (DKL): 23.29 - Cost (fit): 112.25 - Cost (constr): 71.30|| Batch (each iter) of size 9 || Time (each iter): 0.09s
Optimization step: 3 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 23.31 - Cost (fit): 182.45 - Cost (constr): 85.02|| Batch (each iter) of size 9 || Time (each iter): 0.10s
Iteration 50 of 200 || Cost (DKL): 23.43 - Cost (fit): 159.42 - Cost (constr): 68.73|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 100 of 200 || Cost (DKL): 22.30 - Cost (fit): 95.59 - Cost (constr): 49.70|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 150 of 200 || Cost (DKL): 21.20 - Cost (fit): 112.01 - Cost (constr): 50.06|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 200 of 200 || Cost (DKL): 20.72 - Cost (fit): 104.30 - Cost (constr): 53.42|| Batch (each iter) of size 9 || Time (each iter): 0.09s
-- Time reparameterization --
Iteration 1 of 200 || Cost (DKL): 20.72 - Cost (fit): 190.25 - Cost (constr): 72.73|| Batch (each iter) of size 9 || Time (each iter): 0.10s
Iteration 50 of 200 || Cost (DKL): 20.72 - Cost (fit): 87.13 - Cost (constr): 41.18|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 100 of 200 || Cost (DKL): 20.72 - Cost (fit): 102.05 - Cost (constr): 43.72|| Batch (each iter) of size 9 || Time (each iter): 0.07s
Iteration 150 of 200 || Cost (DKL): 20.72 - Cost (fit): 77.64 - Cost (constr): 54.73|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 200 of 200 || Cost (DKL): 20.72 - Cost (fit): 107.69 - Cost (constr): 42.10|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Optimization step: 4 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 20.71 - Cost (fit): 83.48 - Cost (constr): 57.58|| Batch (each iter) of size 9 || Time (each iter): 0.07s
Iteration 50 of 200 || Cost (DKL): 19.77 - Cost (fit): 157.81 - Cost (constr): 93.12|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 100 of 200 || Cost (DKL): 18.75 - Cost (fit): 127.68 - Cost (constr): 49.10|| Batch (each iter) of size 9 || Time (each iter): 0.08s
Iteration 150 of 200 || Cost (DKL): 18.15 - Cost (fit): 150.10 - Cost (constr): 41.18|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 200 of 200 || Cost (DKL): 17.73 - Cost (fit): 135.45 - Cost (constr): 47.16|| Batch (each iter) of size 9 || Time (each iter): 0.06s
-- Time reparameterization --
Iteration 1 of 200 || Cost (DKL): 17.73 - Cost (fit): 139.73 - Cost (constr): 60.69|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 50 of 200 || Cost (DKL): 17.73 - Cost (fit): 89.27 - Cost (constr): 53.93|| Batch (each iter) of size 9 || Time (each iter): 0.07s
Iteration 100 of 200 || Cost (DKL): 17.73 - Cost (fit): 108.91 - Cost (constr): 63.02|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 150 of 200 || Cost (DKL): 17.73 - Cost (fit): 104.92 - Cost (constr): 50.13|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Iteration 200 of 200 || Cost (DKL): 17.73 - Cost (fit): 121.70 - Cost (constr): 41.42|| Batch (each iter) of size 9 || Time (each iter): 0.06s
Optimization step: 5 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 17.75 - Cost (fit): 910.51 - Cost (constr): 41.22|| Batch (each iter) of size 86 || Time (each iter): 0.22s
Iteration 50 of 200 || Cost (DKL): 26.76 - Cost (fit): 618.36 - Cost (constr): 44.85|| Batch (each iter) of size 86 || Time (each iter): 0.22s
Iteration 100 of 200 || Cost (DKL): 30.98 - Cost (fit): 602.58 - Cost (constr): 54.54|| Batch (each iter) of size 86 || Time (each iter): 0.27s
Iteration 150 of 200 || Cost (DKL): 33.82 - Cost (fit): 613.27 - Cost (constr): 48.94|| Batch (each iter) of size 86 || Time (each iter): 0.21s
Iteration 200 of 200 || Cost (DKL): 37.01 - Cost (fit): 601.11 - Cost (constr): 45.43|| Batch (each iter) of size 86 || Time (each iter): 0.28s
-- Time reparameterization --
Iteration 1 of 200 || Cost (DKL): 37.01 - Cost (fit): 536.88 - Cost (constr): 42.77|| Batch (each iter) of size 86 || Time (each iter): 0.35s
Iteration 50 of 200 || Cost (DKL): 37.01 - Cost (fit): 503.89 - Cost (constr): 41.24|| Batch (each iter) of size 86 || Time (each iter): 0.28s
Iteration 100 of 200 || Cost (DKL): 37.01 - Cost (fit): 606.19 - Cost (constr): 44.02|| Batch (each iter) of size 86 || Time (each iter): 0.21s
Iteration 150 of 200 || Cost (DKL): 37.01 - Cost (fit): 464.64 - Cost (constr): 59.21|| Batch (each iter) of size 86 || Time (each iter): 0.22s
Iteration 200 of 200 || Cost (DKL): 37.01 - Cost (fit): 505.09 - Cost (constr): 42.63|| Batch (each iter) of size 86 || Time (each iter): 0.21s
Optimization step: 6 out of 6
-- Regression --
Iteration 1 of 200 || Cost (DKL): 37.12 - Cost (fit): 550.92 - Cost (constr): 50.04|| Batch (each iter) of size 86 || Time (each iter): 0.22s
Iteration 50 of 200 || Cost (DKL): 38.77 - Cost (fit): 459.65 - Cost (constr): 43.52|| Batch (each iter) of size 86 || Time (each iter): 0.22s
Iteration 100 of 200 || Cost (DKL): 41.05 - Cost (fit): 522.94 - Cost (constr): 43.02|| Batch (each iter) of size 86 || Time (each iter): 0.31s
Iteration 150 of 200 || Cost (DKL): 41.90 - Cost (fit): 427.11 - Cost (constr): 44.36|| Batch (each iter) of size 86 || Time (each iter): 0.22s
Iteration 200 of 200 || Cost (DKL): 42.45 - Cost (fit): 442.68 - Cost (constr): 56.11|| Batch (each iter) of size 86 || Time (each iter): 0.21s
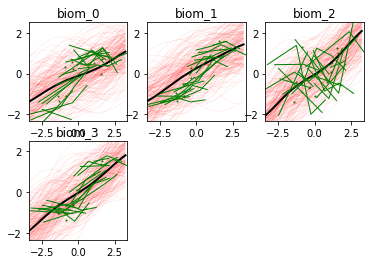
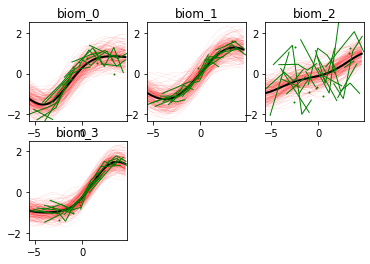
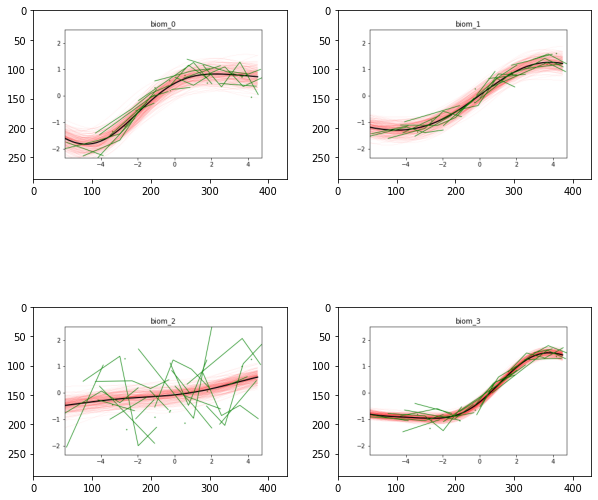
And here is the output of our model: the biomarkers show different progression shapes, and different variability of the individual measurements.
model.Plot()
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
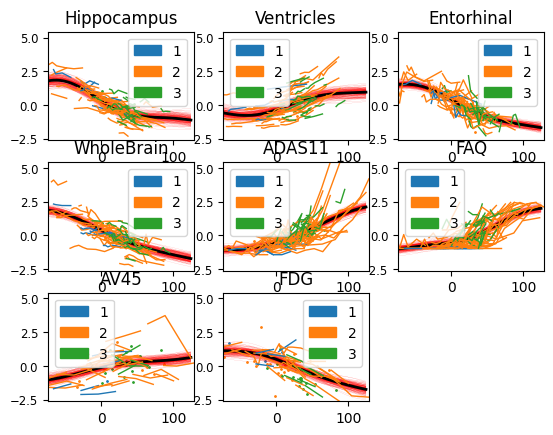
model.Plot(save_fig = './real/')
model.Plot(save_fig = './real/', joint = True)
plt.figure(figsize=(6,6))
timing = plt.imread('./real/change_timing.png')
plt.imshow(timing, aspect='auto')
plt.tight_layout()
plt.title('Estimated trajectories timing')
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
/usr/local/lib/python3.7/dist-packages/numpy/core/_asarray.py:83: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
return array(a, dtype, copy=False, order=order)
Text(0.5, 1.0, 'Estimated trajectories timing')
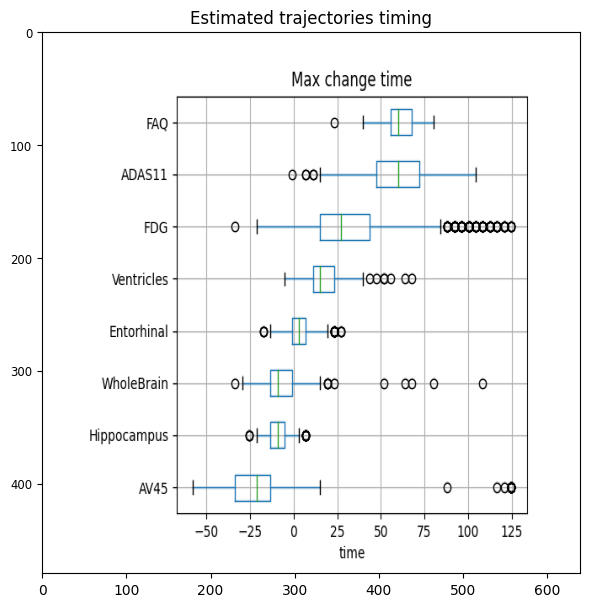
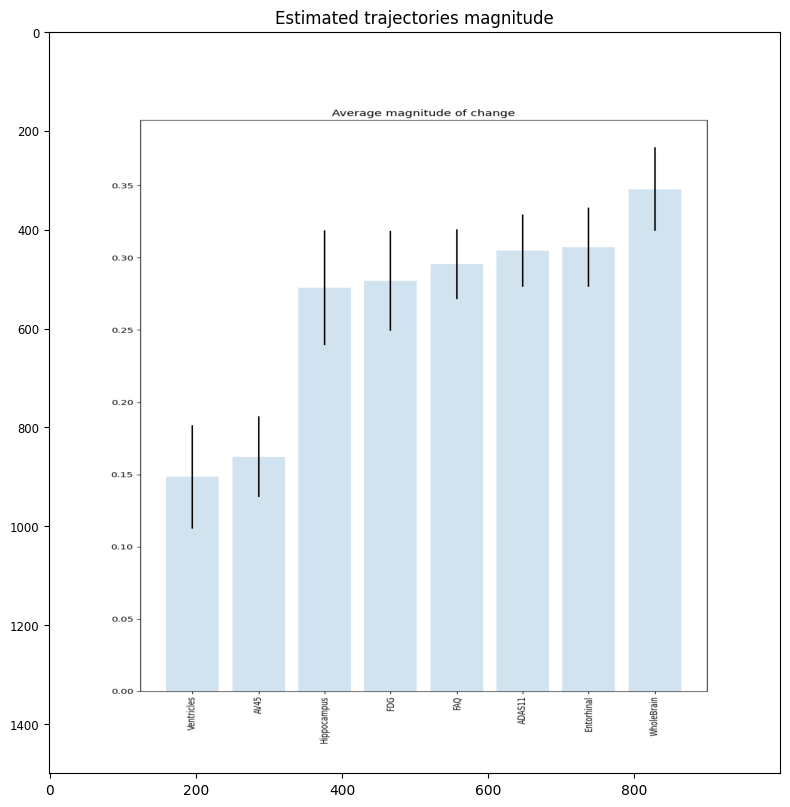
The orderning of the biomarkers reflects the progression curves estimated above. The biomarkers showing the earliest changes are Hippocampus, whole brain and AV45, although the timing of this latter biomarker is more uncertain. The abnormality of entorhinal cortex and ventricles appears later. The changes of glucose metabolism are more spread towards the latest stages of the disease, while the clinical scores FAQ and ADAS11 are the last to reach abnormal values. This figure is quite in agreement with the known biomarker progression reported for Alzheimer’s disease.
plt.figure(figsize=(8,8))
timing = plt.imread('./real/change_magnitude.png')
plt.imshow(timing, aspect='auto')
plt.tight_layout()
plt.title('Estimated trajectories magnitude')
Text(0.5, 1.0, 'Estimated trajectories magnitude')
We can finally predict the disease severity associated with each individual, and compare these estimates group-wise.
pred_time_shift = model.PredictOptimumTime(pseudo_adni, id_var='RID', time_var='Time')
/usr/local/lib/python3.7/dist-packages/torch/tensor.py:474: UserWarning: non-inplace resize is deprecated
warnings.warn("non-inplace resize is deprecated")
# This command creates another .csv file
pred_time_shift.to_csv('./real/predictions.csv')
diag_dict = dict([(1,'NL'),(2,'MCI'),(3,'AD')])
pred_time_shift.reset_index(inplace=True)
# This command creates another .png file
#optim_time = model.Diagnostic_predictions(predictions, verbose = True, group = [diag_dict[i] for i in group], save_fig = './real/')
pred_time_shift
| RID | Time | Time Shift | |
|---|---|---|---|
| 0 | 0 | 0 | 47.603824 |
| 1 | 1 | 0 | 6.981236 |
| 2 | 2 | 0 | 13.751667 |
| 3 | 3 | 0 | 74.685547 |
| 4 | 4 | 0 | 122.078564 |
| ... | ... | ... | ... |
| 166 | 166 | 0 | 67.915117 |
| 167 | 167 | 0 | -67.493503 |
| 168 | 168 | 0 | 54.374256 |
| 169 | 169 | 0 | 54.374256 |
| 170 | 170 | 0 | 61.144688 |
171 rows × 3 columns
rid_group = pseudo_adni.loc[~pseudo_adni['RID'].duplicated(),][['RID','group']]
group_and_ts = rid_group.merge(pred_time_shift, on = 'RID')
group_and_ts = rid_group.merge(pred_time_shift, on = 'RID')
fig, ax = plt.subplots(figsize=(8,6))
for label, df in group_and_ts.groupby('group'):
if len(df['Time Shift'])>1:
df['Time Shift'].plot(kind="kde", ax=ax, label= diag_dict[label])
else:
print('Warning: ' + label + ' group has only 1 element and will not be displayed')
plt.legend()
<matplotlib.legend.Legend at 0x7f4aa1c4e650>
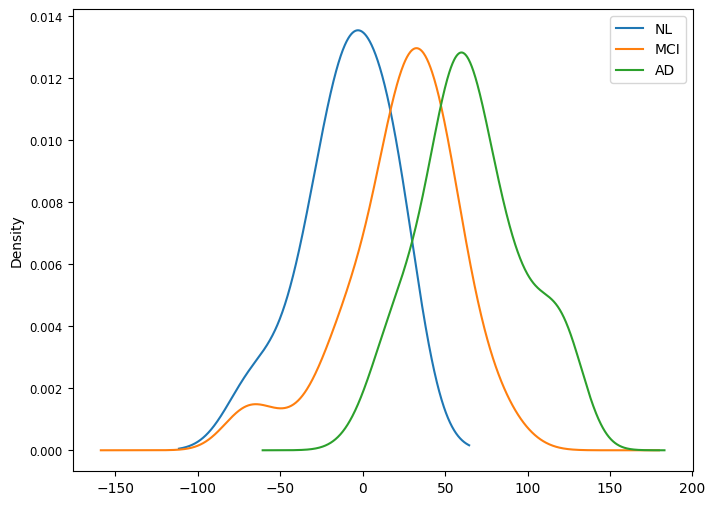
Patients with AD appear significantly more advanced on the disease time-axis as compared to MCI and healthy, while MCI subjects are in between healthy and AD groups.